
Believe it or not, there was once a world of search engines that did not contain AI summaries filled with nonsensical garbage. There was once a world of search engines that did not always serve up a Wikipedia article or Reddit thread. There was once a world of search engines where exciting things could happen and dreams could be forged, all at the press of a button. Well close enough anyway.
In fact the real excitement was the wealth of choice we had available, and the battle between these companies, forging their path on this brand new landscape.
Before the WWW
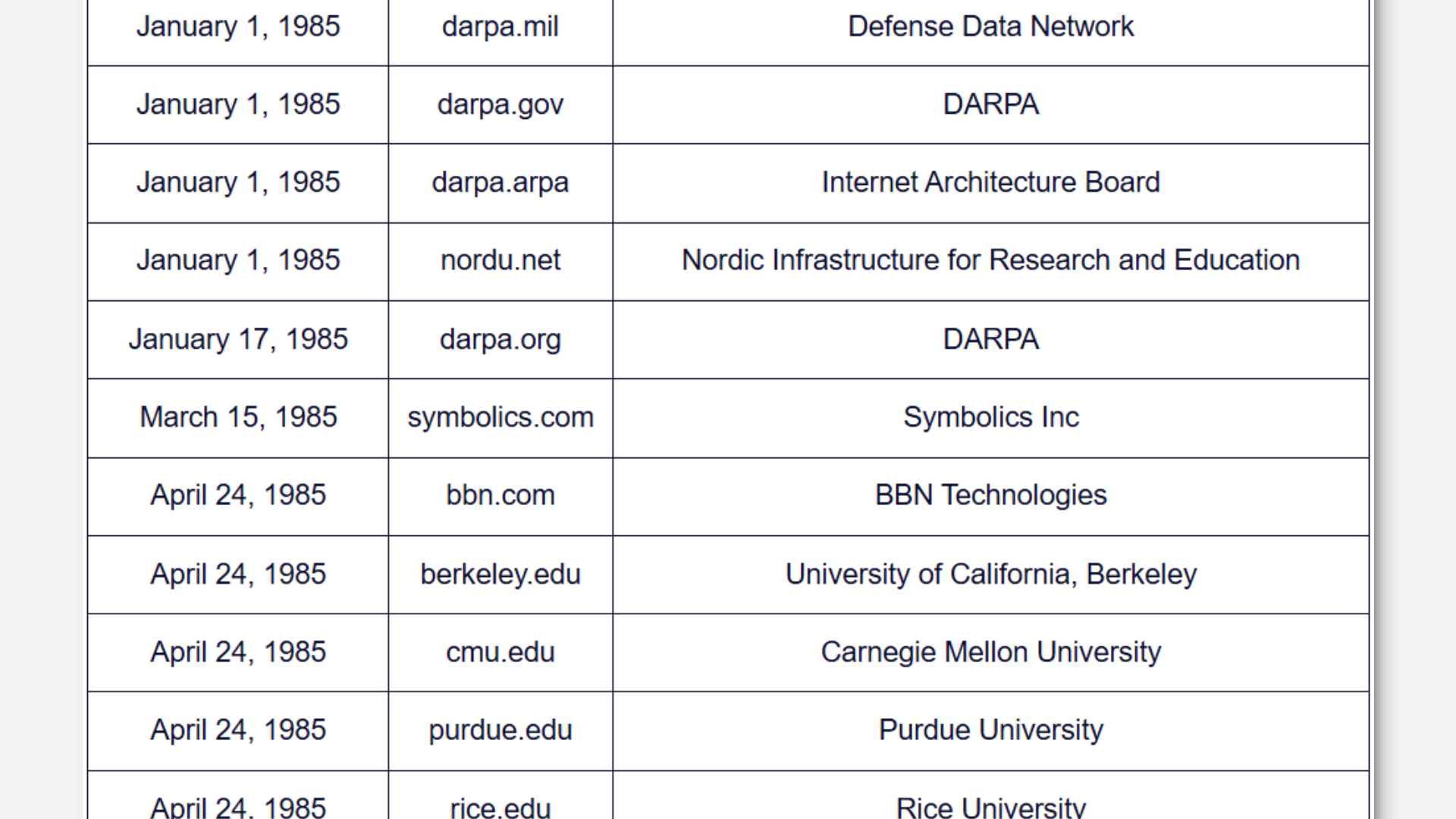
On the 15th March 1985, the first internet .com domain was registered; symbolics.com.12 Symbolics was a computer manufacturer located in Cambridge, Massachusetts, that from 1980 had created a range of computers utilising the Lisp programming language; Lisp Machines. Technically the first commercial computer workstations. So it’s no surprise they wanted the first internet domain too.

By the end of 1985, there was only a handful of domains registered. Indeed, even by 1989, pickings were sparse3. But we’re talking a time before even the World Wide Web. A working version of which wasn’t ready until the end of 1990. So before this point, searching the internet, in the way we know it now, wasn’t really necessary. You tended to know which domains you wanted to connect to.
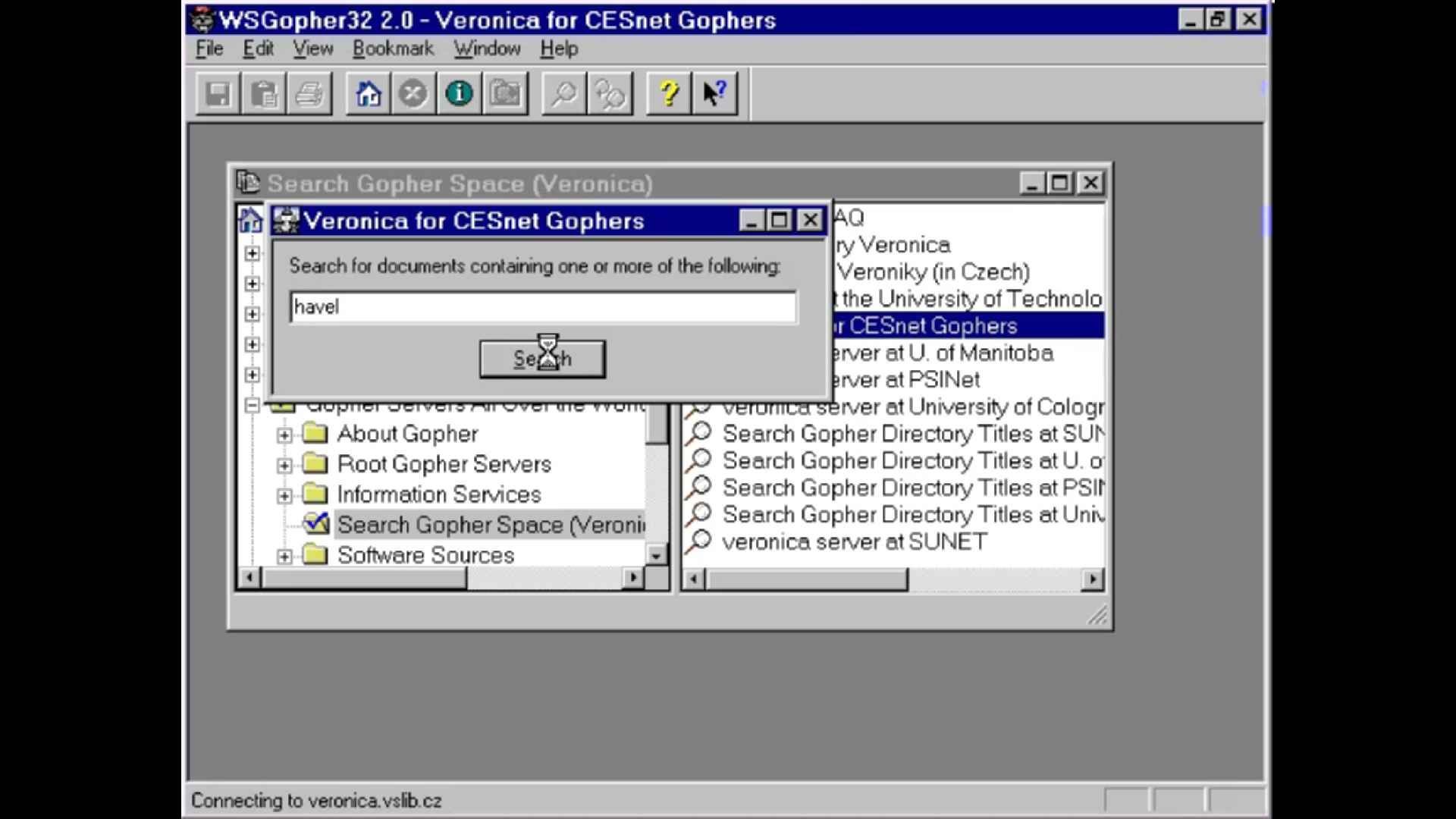
Even so, there were tools, such as Wide Area Information Server Systems4, using Archie5 to index FTP archives, and the using the TCP/IP Application Layer protocol Gopher, which predated HTTP and had its own search engines such as Jughead6 and Veronica.
Searching the Early Web
But the web as we know it was started here. This NeXT machine, used by Sir Tim Berners-Lee was actually the world’s first web server, hosting the first web page at nxoc01.cern.ch/hypertext/WWW/TheProject.html.78

This webpage would soon include a list of other pages that you could navigate to through HTML. The link “What’s out there” breaking down various pages by Subject and Type. We could look at the US weather, some politics, and of course, an online link to the Bible. Our lord and saviour is always ahead of the curve.

But this was a limiting way to explore the web. It depended on these links being updated by whoever was looking after the page. So if you created a new website, on a new domain, you might have to kindly request that your website be added.
This form of page would quickly become known as a link page, or for the larger versions, organised by category; a directory. A hand picked list of sites that you could visit and explore from.
That’s fine when there’s a few thousand websites in the world, but with the Mosaic web browser launching in late 1993, things were taking off at a rapid pace.

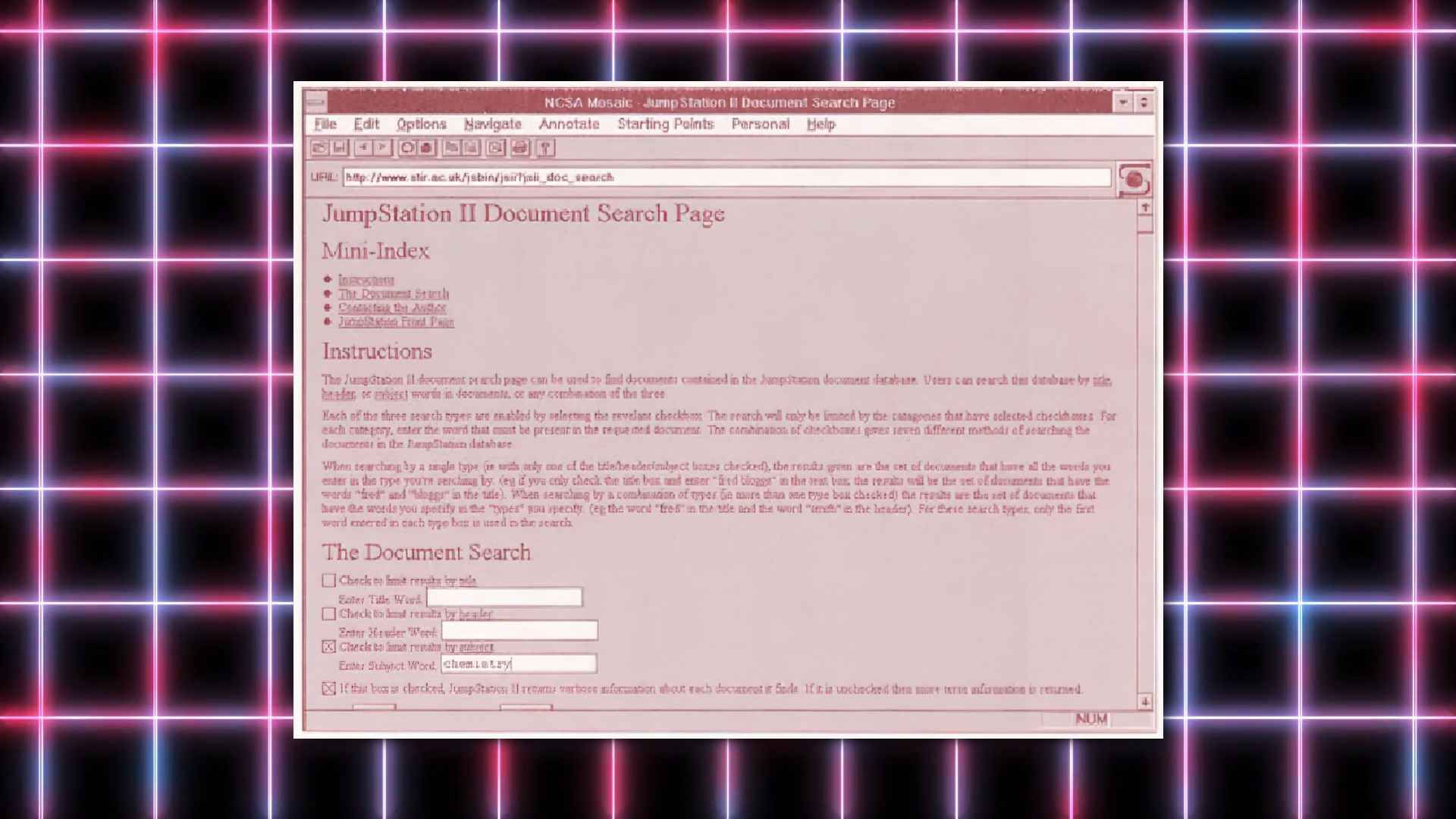
But it wasn’t commercial enterprise that attempted to create a tool to shine a light into the unknown, it was University of Stirling graduate Jonathon Fletcher, who decided to put the Scottish university’s internet server to use.
Search engines of sorts already existed, such as W3Catalog and Aliweb9. However, neither of these are like the search engines we know today. W3Catalog just referenced existing link pages on the web and updated from there, whilst Aliweb required website owners to notify of their existence. However Jonathon Fletcher’s JumpStation combined the three essential elements of a modern search engine; crawling, indexing and searching.10
You see, a search engine isn’t some magic portal to the web. It’s just a database, held on a server, that periodically gets updated as and when new content is found. It’s the job of the crawl-bot to find this new content, and it does that by visiting its known sites and following the links within. If a site has linked to a new page or site then it’s added to the search engine’s database. Each page added to the database is indexed, in these early days, usually just by the words found within it. Then a query form is made available to a visitor, so that they can search this indexed database. From which results are then presented to the searcher in the form of a URL list.


JumpStation, launched on 12th December 1993 did all of this. Although, in a bid to save resources, only document titles and webpage headings were indexed at this point, which kinda did the job back then. By the time the site closed down in late 1994, the database held 275,000 entries, spanning 1,500 servers.
The Search Engine Era is Born…
Other search tools popped up in that time, but WebCrawler, released in April 1994 was the first search engine that actually indexed entire webpages, allowing users to search for any words within those pages. This proved so useful that it became the standard for search going forward.
By this time Infoseek, founded by Steve Kirsch, had also rolled out, although initially as a pay to use service. Something it would later drop, becoming the default search engine for Netscape Navigator in 1995.
Lycos, what began as a research project headed by Michael Loren Mauldin of Carnegie Mellon University appeared in July 1994, and quickly gained popularity. The name Lycos was actually derived from Lycosidae, the scientific name for the “wolf spider”11; an excellent hunter that catch prey by finding it, instead of luring it into a web. Lycos has full crawling, and indexing capability, but was heralded for it’s simplicity. Even the results page was just a plain list of links relevant for the keyword. Within a month of launch Lycos recorded more than 400,000 pages and documents.12
By the start of 95, Yahoo! had built upon their earlier directory feature by launching Yahoo Search, which allowed users to search the Yahoo! Directory, and so actually not a true search engine, BUT due to the quality of its directory, it became popular quickly.
But these engines would face serious competition from Altavista. Which by it’s own reckoning became the most comprehensive search engine on the web.
Even before it’s launch, there was intense hype around AltaVista. Within weeks, hundreds of articles were written on how it’s “Super-Spider” could help you find long lost friends or list all sites pointing to your page. It seemed that a small group of friends and colleagues had indexed the entire web and were ready to serve it to millions of users within fractions of a second.

The “Super-Spider” in question was actually called “Scooter”. Scooter was AltaVista’s multi-threaded web crawler, and rather than collecting just titles, or even key words and sentences, it would instead collect complete pages, which were then indexed in their entirety, ready for searching. What’s more, it did this continuously, and quickly. Meaning that if a new website appeared on the web, it could be retrieved from AltaVista in hours rather than days or even weeks.
Most search engines at the time were running out of university research labs, utilising their powerful machines, but AltaVista was a venture launched by Digital Equipment Corporation, and they had the technology to boot. This included the Alpha 8400 TurboLaser server13. A beast of a system which contained 12 EV5 processors, each running at 300MHz, alongside a whopping 28GB of RAM. When you bear in mind the average desktop PC then was a 486 running at 50MHz with 8MB of RAM, this is obscene. But then, so was the price, with each server costing around half a million dollars.

This then was when search really started to get serious. Altavista had started a race which meant Lycos and Yahoo had to step up their game. But it also meant that competition came thicker and faster.
Search Gets Serious
By the end of 1996, AltaVista was handling 19 million requests per day, and had a database covering over 30 million pages. But Lycos was still dominating, in terms of volume at least, with its crawlers having apparently indexed 60 million pages.
This was starting to become a war of stats, but really, this isn’t what people wanted. People wanted clarity and they wanted results that were relevant.
That’s where RankDex came onto it’s own14. Defining an important part of search, and that is, how results are ranked. Originally, results were just delivered how they fell out of the database. Altavista started using other factors, such as the how frequently the keyword being searched for appeared on the page, serving the pages with the highest frequency first. But this quickly led to problems, such as websites spamming their pages with popular keywords in order to artificially inflate their rankings.
Rankdex then would begin using backlinks to measure the quality of websites. That is, if a website or page has more hyperlinks directed to it, then it’s more likely to be a reputable source of information, and therefore the content it contains is likely to be more relevant to the searcher. In these early days especially, this was an incredibly effective way of ranking content.

At around the same time, Larry Page and Sergey Brin were working on a little search service called BackRub; the predecessor to Google. With it’s crawl bots starting to scour the web in March 96, running from Stanford’s Sun Ultra II web servers15.

But by May, the online division of Wired magazine, HotWired, in collaboration with American Internet Service Provider Inktomi would launch the HotBot Search Engine. Now HotBot claimed to be even better than Altavista. Having indexed 54 million pages and documents, and being able to refresh this entire index once a week, this was probably the most up to date database of the web the 90s would see.

Things were indeed hotting up. Even before1997, the search engine world was saturated, and this isn’t even including the Metasearch engines.
Otherwise known as Search Aggregator, these sites used the databases and tools of search engines to create their own results. This included sites like Dogpile, excite! and MetaCrawler, that could arguably serve up better results without building their own foundations.
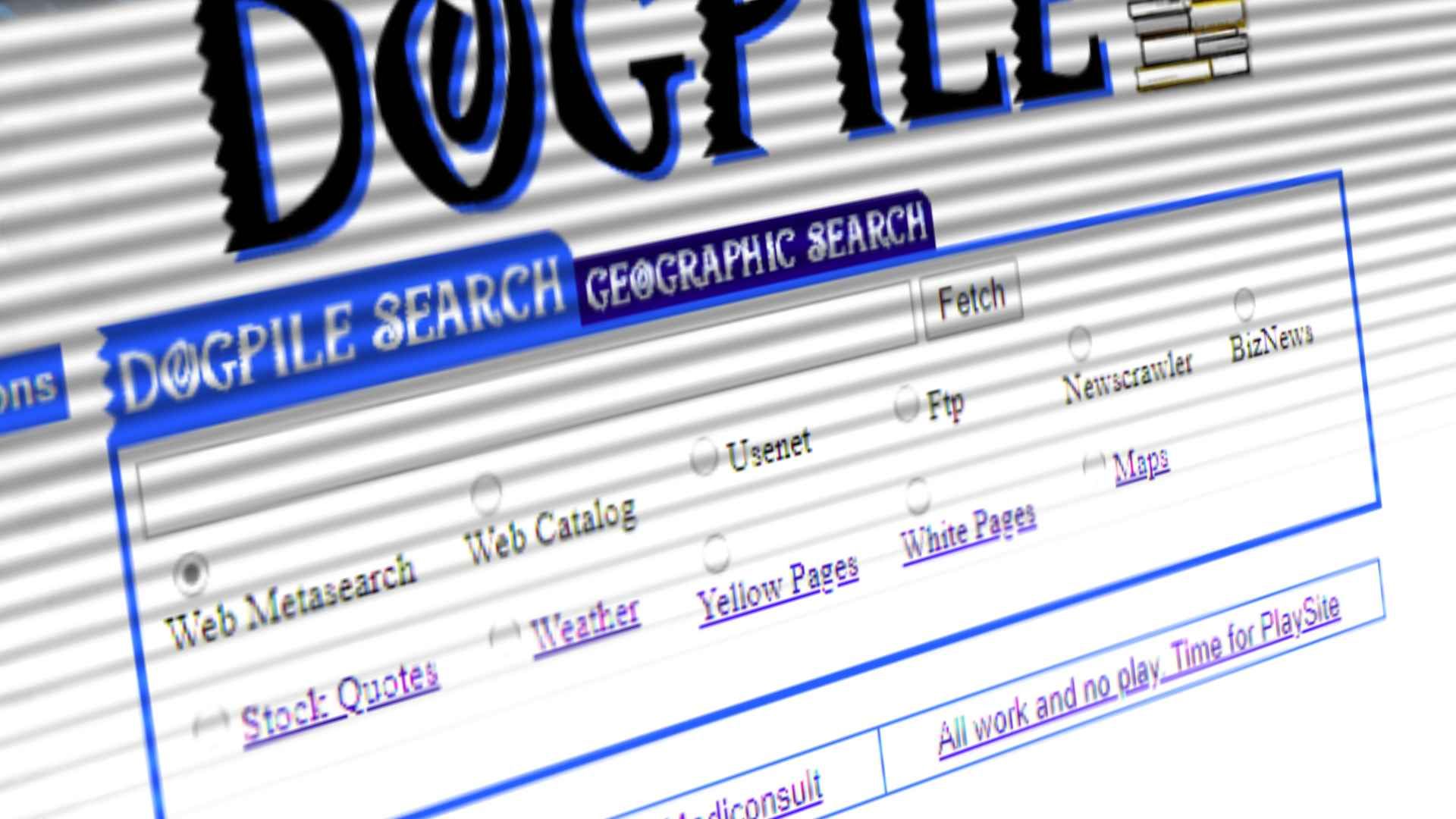
Dogpile pulled queries from Yahoo, Lycos, Excite, Webcrawler, Infoseek, AltaVista, HotBot, WhatUSeek and the World Wide Web Worm, as well as having the ability so earch Usenet, making it an incredibly comprehensive tool. Whilst Excite offered services such as email and customisation from the go, giving them distinct advantages over competitors.
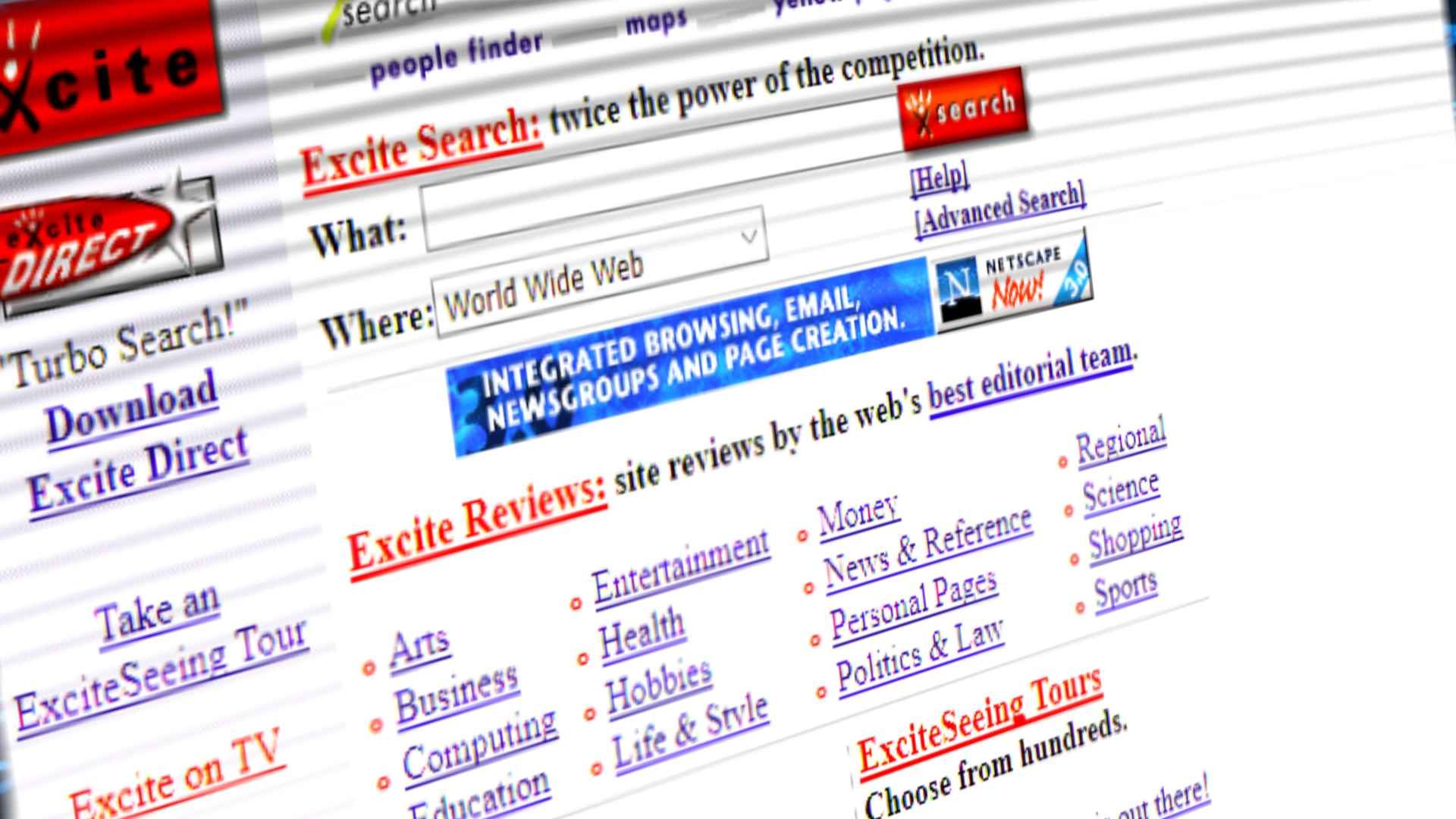
Like most of these sites, Metacrawler was again, created by a university graduate, Erik Selberg. By the end of 1996 Metacrawler was receiving 150,000 queries per day, which was far too much for the University of Washington’s DEC AlphaStation servers to keep up with, and so it become a commercial entity under NetBot Inc, which was shortly after purchased by Excite! Excite! utilised features of Metacrawler to create the Network Shopping Channel, demonstrating increasingly commercial ways these engines were taking to make money, as some morphed more into web portals, rather than just search engines.
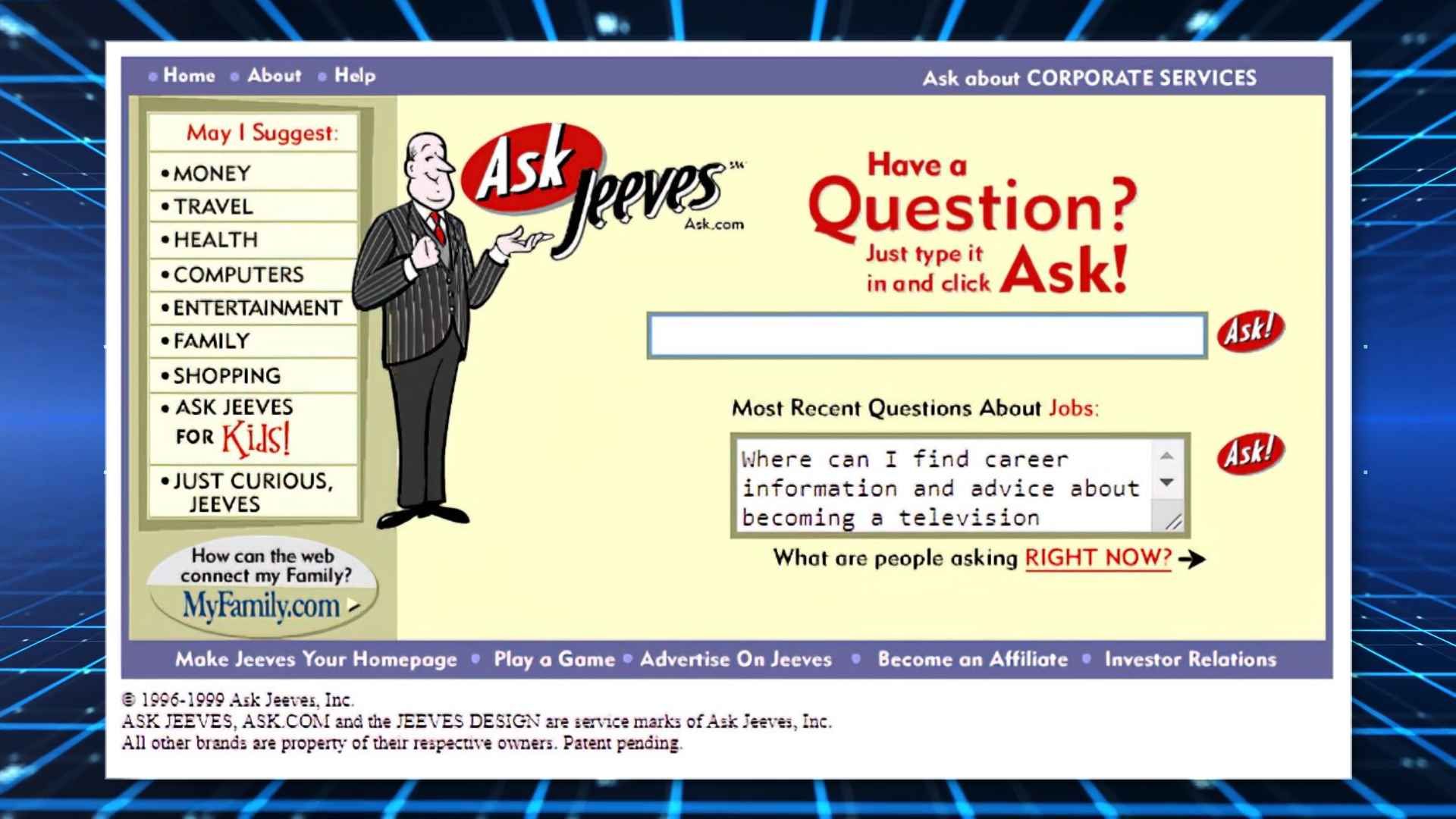
But even with this crowded area, the internet was growing at an exponential rate16, and more casual users demanded a more casual experience. So, in April 97 Ask Jeeves saw a gap in the market. Unlike other engines which had their own query formatting, Jeeves was a natural language engine. The idea here then was that you could type your question in a very human form, and get search results that were appropriate. Ask Jeeves quickly began to build up an entire brand around their search, including books and butler themed promotional items, capturing a niche but stable portion of the market.
Of course this was a time for innovation, and there was plenty still to be done.
The Dawn of Google
On the 15th September 97 Google.com was registered. Larry and Sergey having already tested the premise from Stanford’s website and decided that BackRub was probably not the best name for their engine.
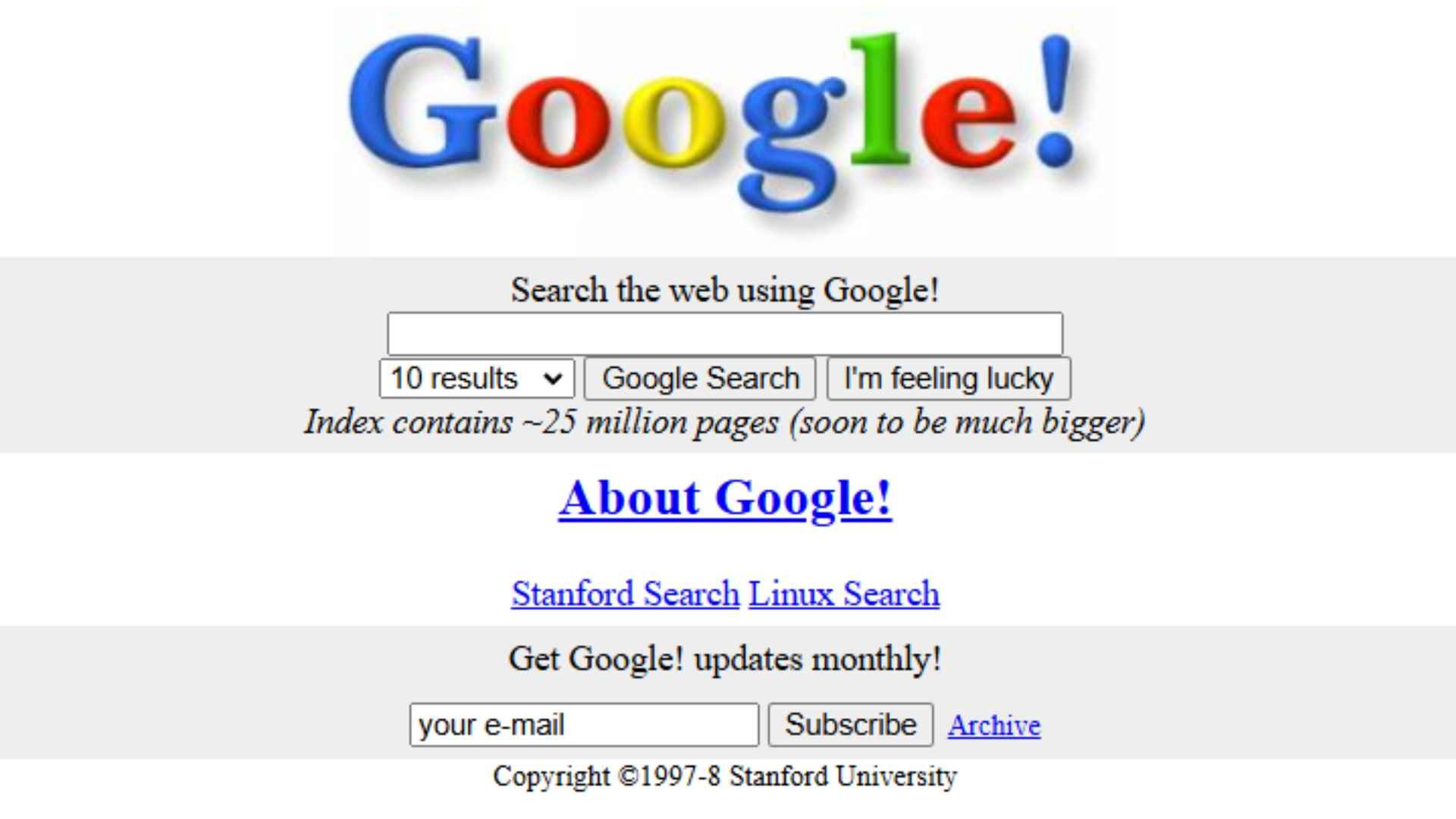
But Google wouldn’t actually launch until September 1998, around the same time that Microsoft decided to get in on the act with the MSN Search Portal, which actually used search results from Inktomi, the same database that HotBot ran on.
This database was also used by Direct Hit Technologies for their Popularity Search engine which actually incorporated previous search activity to serve up more relevant results17. What we were seeing here was really the emergence of features that would at some point, be common across all the main search engines.
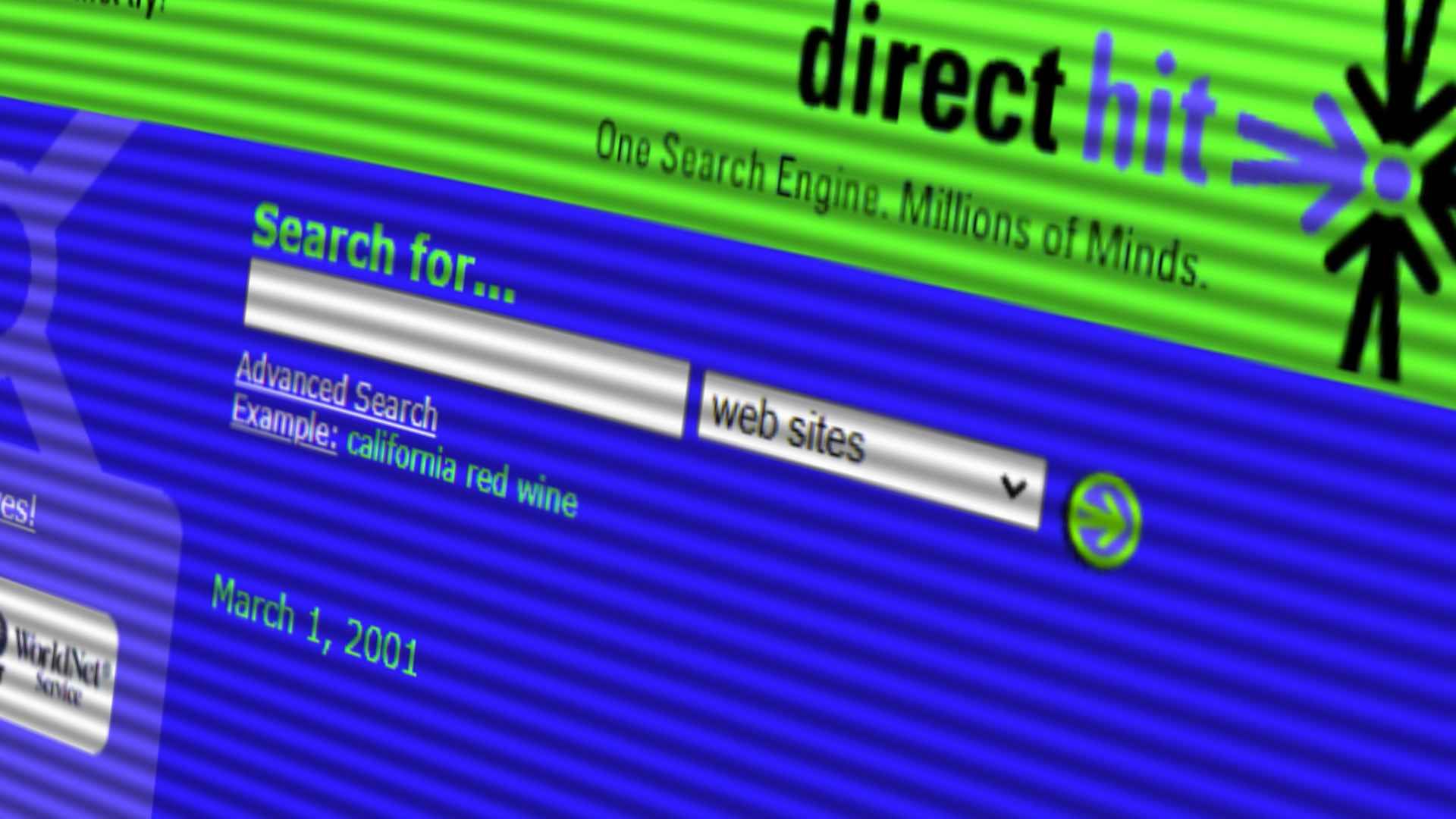
But by this point, things were crazy.
We not only had a plethora of search engines, and search engines specific for other languages, such as Russia’s Yandex, we also had much more comprehensive directories. These directories, such as DMOZ, tried to concentrate of quality content. A curated batch of sites and pages, rather than opening you up to the slurry of content available on the web, and sometimes, these were actually the best choice.
But even putting the directories aside, if you combine all the Metasearch engines and search engines there were hundreds to choose from. Not to mention the spinoffs such as Yahooligans for kids and web portals that ISPs used, which were usually either Metasearch engines themselves or using the technology of a product such as Lycos, Inktomi or Altavista18. Usually, people would flock to whichever ones were suggested to them, a whole set business of websites even appeared specifically to investigate and recommend which search engine to use….19
This was a big money industry, one of the biggest… these pages were indeed the portal to the internet, and so the main contenders fired shots with big marketing campaigns. Offering free services, better features and whatever else they could think of. However, it was probably Yahoo who struck the chord most, with their humorous TV adverts.

As we went into the millennium, the main contenders were shining through.
AltaVisa, Lycos, HotBot and Yahoo, with Excite dominating the Metasearch world. MSN were also packing punches, mainly because their homepage was the default landing page for Internet Explorer, those cheeky rascals…. but regardless, that little company called Google were starting to get people’s attention, and they were getting it fast.
In late 1999, Sergey Brin and Larry Page had decided that Google was taking up too much of their study time and offered the business to Excite for $750,000. The CEO of Excite, George Bell decided it was too expensive and unnecessary, with Google having less than 10% of the market share at the time.
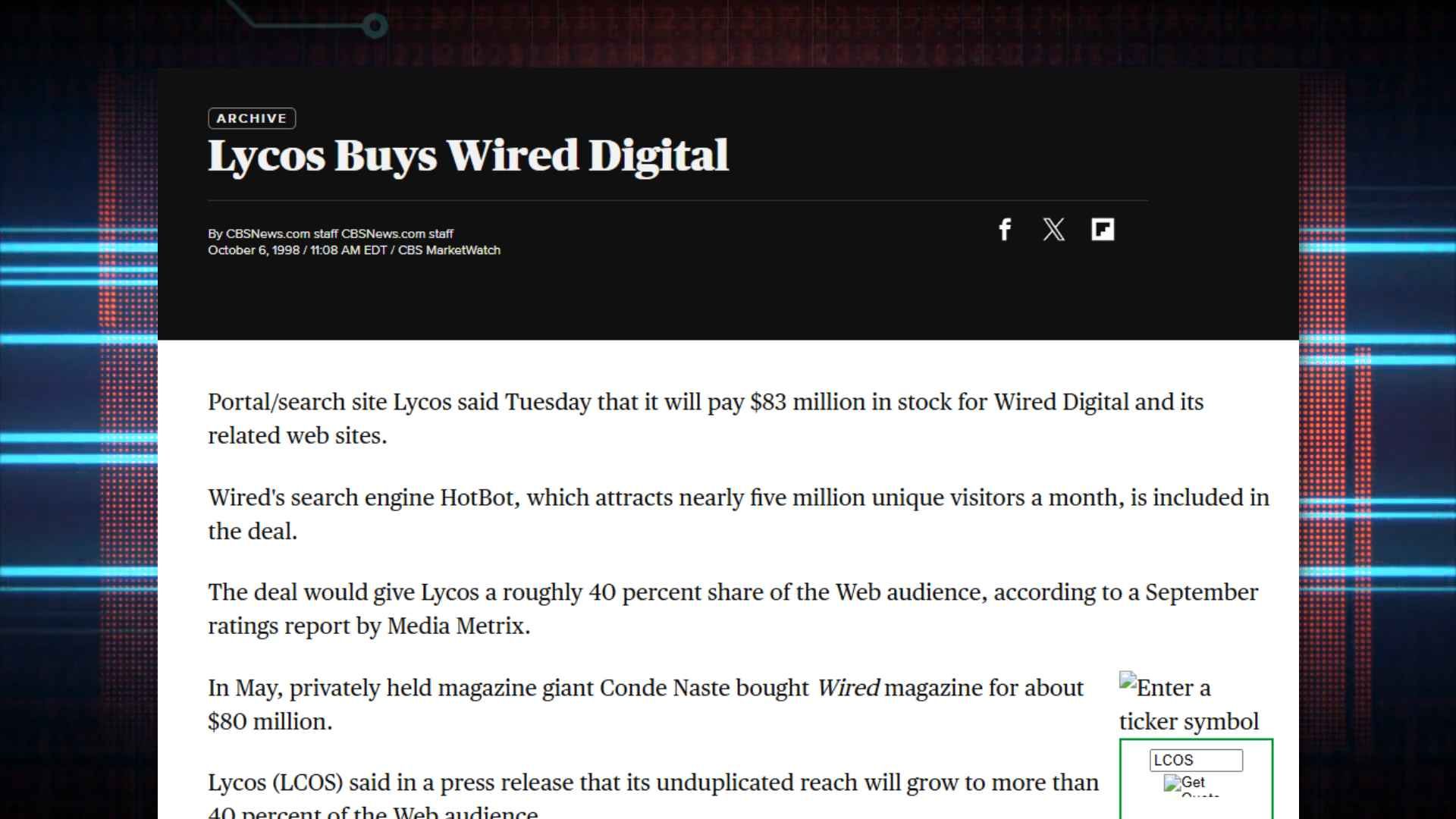
Google noticed that not everyone could win this race, this was a time of consolidation. Much like the early micro wars of the 80s, a few would come out dominant. Deals such as Lycos acquiring Wired Digital, and therefore the HotBot engine would become the norm.
But with the deal with excite dead, Google realised that people were starting to hone on on their advantages. The first was it’s simple design, much like Lycos originally started, but by now had progressed into mug’s eyeful. The second was the unintrusive advertising, Brin and Page were against advertising altogether, but allowed some simple text ads (based on searched keywords) to pay for their venture. The third was Google’s pagerank algorithm that used various factors to rank search results. This method actually borrowed a lot from Robin Li’s RankDex, which is actually cited in their 1998 patent, but added in various other factors, that would grow and adapt over time. This quickly put Google ahead of competitors in terms of relevant search results and this did not go unnoticed by Search comparison sites and the general media.
The fourth reason however, was the name. Google. It was Larry Page himself who first wrote “Have fun and keep googling” on an mailing list email from July 199820, two months before the company had even launched. From there the verb quickly took off, giving the world a concise word for “searching the internet”.

From there, things really did progress quickly….
By 2001, Google’s main competition was really msn and Yahoo!21 Although Microsoft’s business practices and their antitrust case for monopolising internet browsers had left a bitter taste in the mouths of some.
In 2002 Yahoo! would purchase Inktomi, and Overture Services inc.22 which by that point already owned Altavista. Essentially eating it’s competition apart from Google. In fact, up until that point Yahoo! was using Google’s search functionality to power it’s own search, but in 2003 started using their new Yahoo Slurp web crawler to power their own search. By leaning on all their acquisitions, they hoped to use the technology to beat Google at their own game and retake dominance.
This switch actually dented Google’s market share for several months, but the damage was not long term. Although Yahoo had plenty of resources and money to invest in their search, they also had other arms to their business. For Google, it was really their only driving force, and at that point, they already had over 30% share of the market. This enabled them to invest more in their core functionality, creating a runaway success, that left most of their competition for dead.
In March 2004, the dependable Ask.com, formerly Ask Jeeves purchased Excite for 9.3million common shares and $144million in cash23. This was part of a strategy to rejuvenate their search services across the board. However, it was an expensive and futile attempt, and they couldn’t keep up with the search arms race between Google and Yahoo.
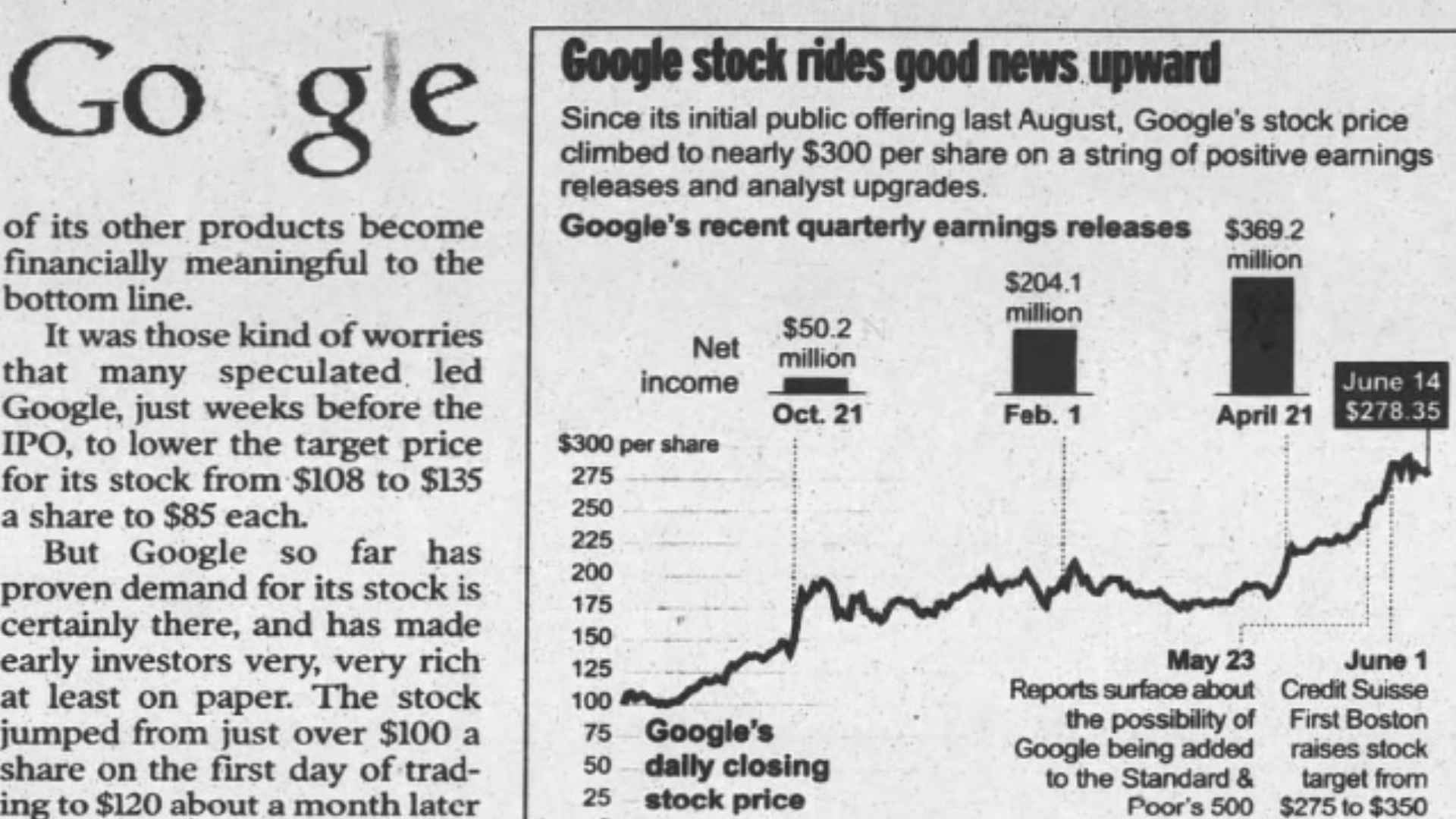
In June 2005 Google was valued at almost $52 billion, making it one of the world’s biggest media companies, and leaving tears in the eyes for Excite who turned down the $750,000 deal.
Most of the prior search companies were just strung out versions of their former selves at this point24. Some tried to adapt. Lycos for example, introduced several media services, including the Lycos phone25 which combined video chat, real-time on demand video and an MP3 player. Lycos would eventually be sold to an internet marketing company based in India in 2010.
In 2008 Yahoo were faced with laying off hundreds of people, having become bloated over the years and now struggling in the face of competition, mainly from Google. Especially with the launch of Google’s Chrome browser, flipping the bird to Microsoft’s earlier business practices and starting the process of toppling Internet Explorer’s dominance.
In February 2008, Microsoft made a bid to acquire Yahoo for $47 billion, which was rejected by Yahoo, leaving Microsoft to focus on building a new search engine, Bing.

In a cruel irony, by 2012 Yahoo were unable to sustain their own search model and switched to using Bing’s technology to power their own site.
The Transition to Today’s Search World
Other search engines would come and go. Some stuck around, focusing on ethics, a lack of advertising or just being a company that wasn’t Google or Microsoft.
But, we never really regained the excitement of those initial Search Engine battles, simply because Google got so good at serving up what people wanted, that no one really needed to go anywhere else.
It’s inevitable.
The early days of products are always an exciting playground of opportunity. Companies fighting each other, and in doing so driving each other forward. But sooner or later, it’s just easier to go with the masses.
Good ole’ reliable convenience.
But should you wish to hark back to the days of old and experience search like it was, there are still a few of the original search engines running. A lot are just fronts using Google or Bing, but some, some are still doing their own thing, and for that, they get my full respect.

Until next time, I’ve been Nostalgia Nerd.
Toodleoo.

Nostalgia Nerd is also known by the name Peter Leigh. They routinely make YouTube videos and then publish the scripts to those videos here. You can follow Nostalgia Nerd using the social links below.
- www.onlydomains.com/blog/what-was-the-first-domain-name-ever-registered/#:~:text=In%201985%2C%20the%20registration%20of,would%20order%20anything%20else%20online. [↩]
- symbolics.com/museum/ [↩]
- h. [↩]
- ldapwiki.com/wiki/Wiki.jsp?page=Wide%20Area%20Information%20Server [↩]
- ldapwiki.com/wiki/Wiki.jsp?page=Archie [↩]
- ldapwiki.com/wiki/Wiki.jsp?page=Jughead [↩]
- first-website.web.cern.ch/node/16.html [↩]
- en.wikipedia.org/wiki/Tim_Berners-Lee#:~:text=This%20NeXT%20Computer%20was%20used,%22vague%2C%20but%20exciting%22. [↩]
- www.informit.com/articles/article.aspx?p=2181834 [↩]
- pagenorth.co.uk/search-engine-optimisation-the-genesis/ [↩]
- wordlift.io/blog/en/entity/lycos/#:~:text=Lycos%20has%20been%20one%20of,to%20site%20using%20page%20links. [↩]
- www.websearchworkshop.co.uk/lycos_history.php [↩]
- www.websearchworkshop.co.uk/altavista_history.php [↩]
- www.tech-insider.org/internet/research/1997/1210.html#test [↩]
- web.archive.org/web/19981111183552/http://google.stanford.edu/ [↩]
- www.researchgate.net/figure/Growth-in-map-use-through-the-Internet-The-rate-of-growth-is-strongly-exponential_fig4_290738742 [↩]
- www.websearchworkshop.com.au/direct-hit-history.php [↩]
- web.archive.org/web/20001010113756/http://www.searchenginewatch.com/reports/alliances.html [↩]
- web.archive.org/web/20000302115806/http://www.searchengineshowdown.com/features/byfeature.shtml [↩]
- www.wired.com/story/just-google-it-a-short-history-of-a-newfound-verb/ [↩]
- www.youtube.com/watch?v=X_2WSGGuVOs [↩]
- www.websearchworkshop.co.uk/yahoo_history.php [↩]
- www.searchenginejournal.com/ask-jeeves-finalizes-iwon-excite-acquisition/537/ [↩]
- gs.statcounter.com/browser-market-share#monthly-200901-202502 [↩]
- www.zdnet.com/home-and-office/networking/lycos-phone-no-thanks/ [↩]




1 Comment
Add Yours →I once worked for OpenText. Internet search was almost perfected in Canada. What a cool group of people.